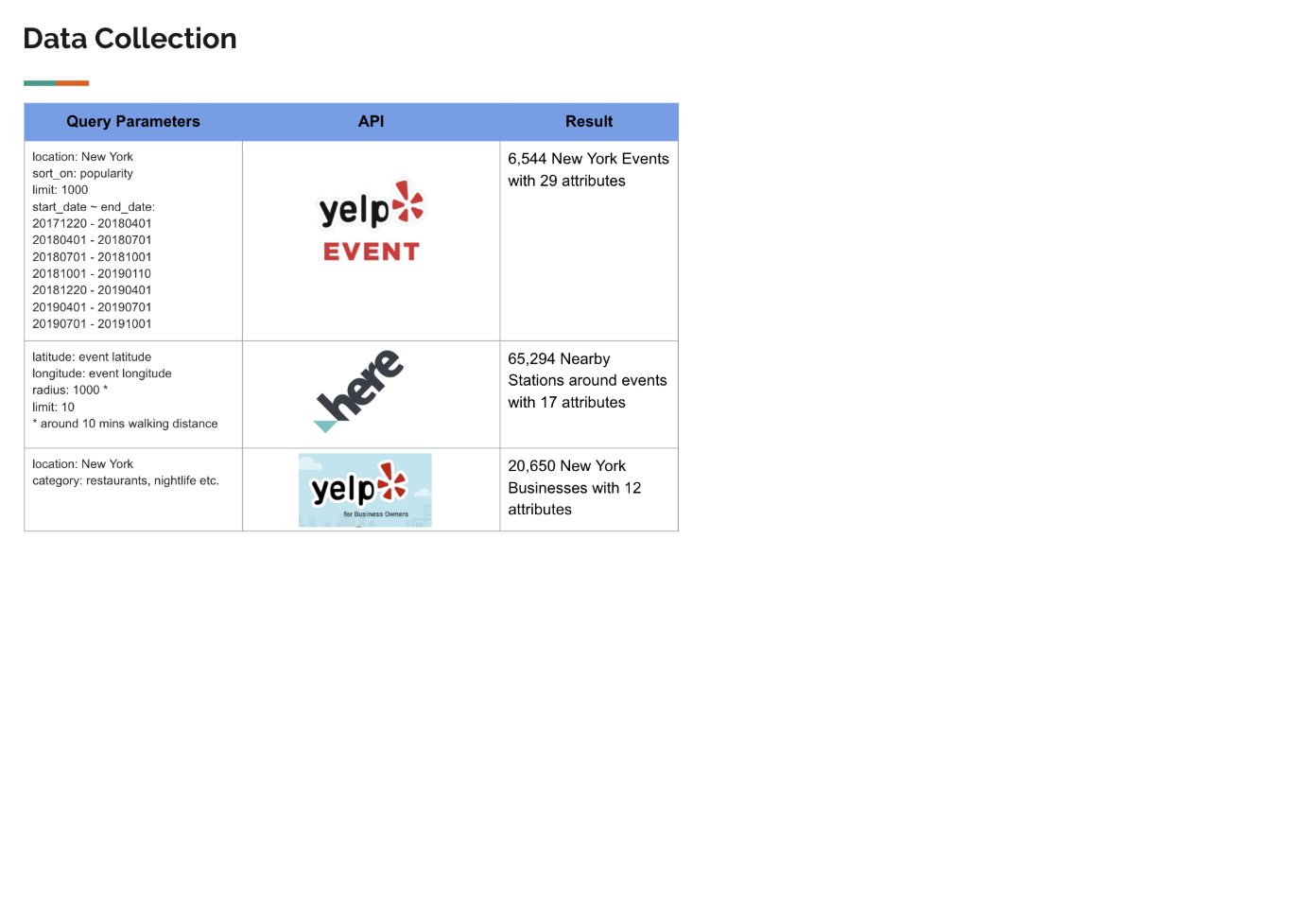
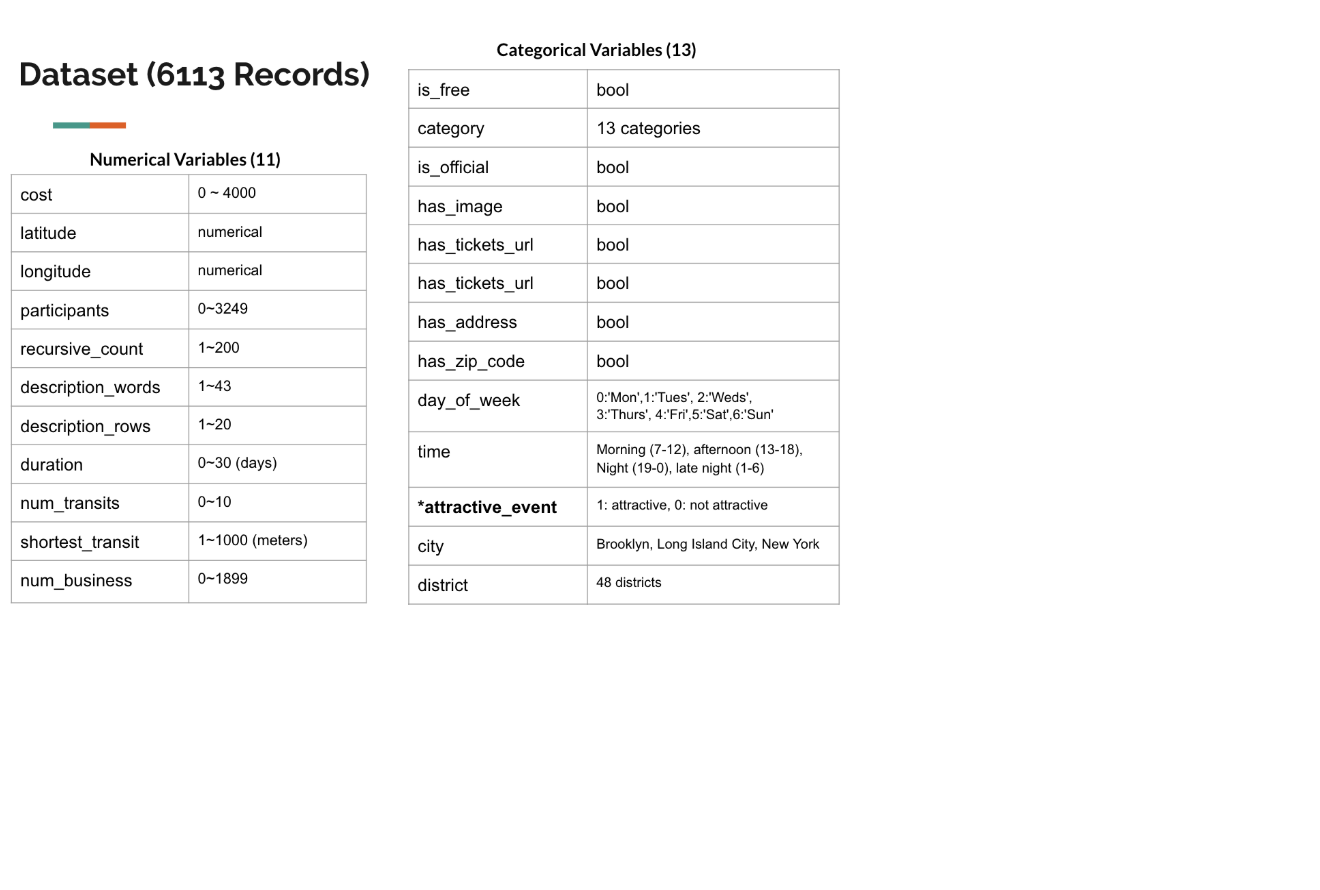
Data Collection
Event date, location, businesses close-by and transportation accessibility are all possible key factors.
This analysis provides valuable insights into understanding people’s decision-making process and day-to-day scheduling. It is especially useful for any hosts to better market their events and attract as many people as possible with shared interests.
According to the Bizzabo Blog, 41% marketers believe that “events are the most effective marketing channel over digital advertising, email marketing and content marketing.” Event-directed marketing strategies increased by 32% since 2017.
There are plenty of traditional statistical analysis conducted on event marketing and management, but little is done through comprehensive machine learning. Our predictive approach captures a wide range of variables by conducting geospatial analysis, predictive modeling and text analysis through the combination of three very different data sets. It adds valuable business strategies to the current event marketing and management industry.